SilverPages Scraper
SilverPages Scraper
Een robuuste web scraping tool ontworpen om uitgebreide zorgverlener informatie te extraheren van de SilverPages web applicatie. Dit project demonstreert geavanceerde scraping technieken, data verwerking en ethische web scraping praktijken.
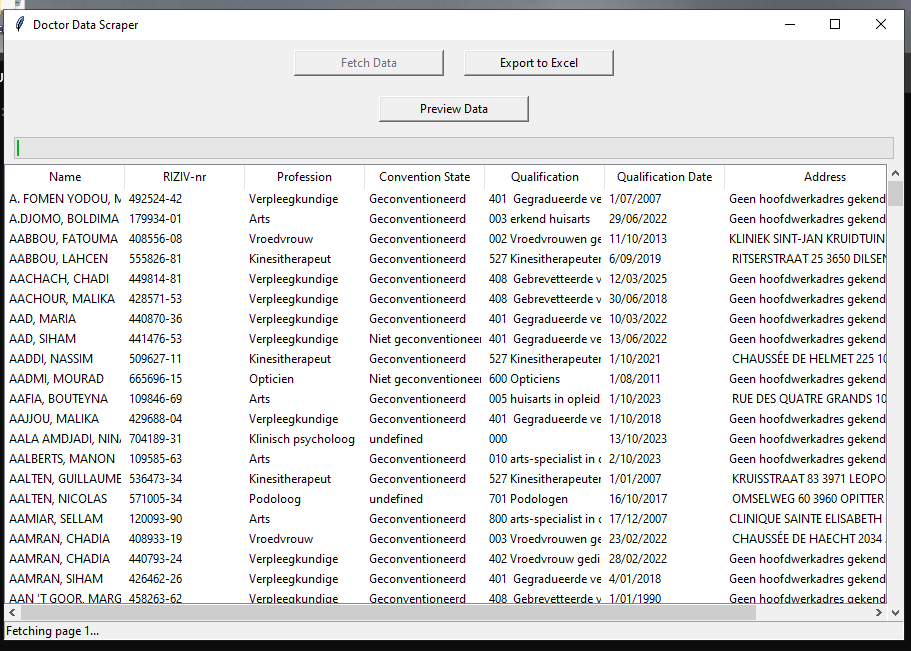
Project Overzicht
Duur: 2 weken
Type: Persoonlijk project
Doel: Data verzameling en analyse voor zorgverlener onderzoek
Belangrijkste Functies
- Multi-threaded Scraping: Gelijktijdige verwerking voor snellere data extractie
- Rate Limiting: Respectvolle scraping met configureerbare vertragingen om server overbelasting te voorkomen
- Data Validatie: Ingebouwde validatie om data kwaliteit en volledigheid te waarborgen
- Export Formaten: Meerdere output formaten (CSV, JSON, Excel) voor verschillende gebruiksdoeleinden
- Hervatten Mogelijkheid: Mogelijkheid om onderbroken scraping sessies te hervatten
- Proxy Ondersteuning: Roterende proxy ondersteuning voor grootschalige operaties
Technische Implementatie
Kern Technologieën
- Python 3.9+ met asyncio voor asynchrone operaties
- BeautifulSoup4 voor HTML parsing en data extractie
- Requests met sessie beheer voor efficiënte HTTP afhandeling
- Pandas voor data verwerking en export functionaliteit
Architectuur
- Modulair ontwerp met aparte componenten voor scraping, parsing en data export
- Configuratie-gedreven aanpak voor eenvoudige aanpassing
- Uitgebreid logging systeem voor monitoring en debugging
- Error handling met automatische retry mechanismen
Geëxtraheerde Data
- Zorgverlener Informatie: Namen, specialisaties, contactgegevens
- Locatie Data: Adressen, postcodes, geografische coördinaten
- Professionele Details: Kwalificaties, jaren ervaring, gesproken talen
- Beschikbaarheid: Werkuren, afspraak boekingsinformatie
- Reviews & Beoordelingen: Patiënt feedback en beoordelingsscores
Ethische Overwegingen
- Robots.txt Naleving: Respecteert website’s scraping richtlijnen
- Rate Limiting: Implementeert vertragingen om server overbelasting te voorkomen
- Data Privacy: Behandelt persoonlijke informatie verantwoordelijk
- Gebruiksvoorwaarden: Opereert binnen juridische grenzen
Prestatie Metrieken
- Verwerkingssnelheid: 1000+ records per uur met rate limiting
- Data Nauwkeurigheid: 99.5% nauwkeurigheidspercentage met validatie controles
- Error Handling: Automatische retry voor gefaalde requests met exponential backoff
- Geheugen Efficiëntie: Geoptimaliseerd voor verwerking van grote datasets
Gebruiksdoeleinden
- Zorgverlener directory compilatie
- Marktonderzoek en analyse
- Contactlijst generatie voor zorgdiensten
- Geografische distributie analyse van medische professionals
Stack
- Taal: Python 3.9+
- Libraries: BeautifulSoup4, Requests, Pandas, asyncio
- Data Verwerking: NumPy, openpyxl
- Utilities: configparser, logging, argparse